Collaborative Thematic Analysis in Qualitative Research

Collaborative thematic analysis (CTA) is a research approach where multiple researchers work together to analyze qualitative research. Like thematic analysis (TA), CTA helps the researchers identify, analyze, and report patterns in data.
In this article, we cover the approach for collaborative thematic analysis, including its benefits, challenges, and best practices. The majority of this article is based on Hemphill’s (2018) frequently cited paper "A Practical Guide to Collaborative Qualitative Data Analysis."
You will also find a practical guide on Hemphill's approach to collaborative thematic analysis and recommendations for how to determine when to use this method.
tl;dr: What is Collaborative Thematic Analysis?
Collaborative Thematic Analysis is a team-based method for analyzing qualitative data. It is a multi-step, collaborative way to create a codebook that closely resembles the process of thematic analysis.
Collaborative Thematic Analysis is an iterative process of researcher triangulation. It involves multiple researchers working together to increase the validity and rigor of qualitative research. The result is a set of themes and subthemes that define the codebook.
Although Hemphill calls this method collaborative qualitative analysis (CQA), we have adapted the steps to match the thematic analysis method.
When to Use Collaborative Thematic Analysis
Collaborative Thematic Analysis is a valuable approach used in various situations to analyze qualitative data. You can use when CTA when you want to:
Improve research rigor, trustworthiness, and quality.
Analyze large datasets that require multiple researchers.
Integrate multiple perspectives into one study.
Mentor new qualitative researchers or work with students.
Analyze historical or archival data from multiple perspectives.
Work in interdisciplinary research teams with varying levels of familiarity with qualitative research methods.
Pros and Cons of Collaborative Qualitative Analysis
Collaborative Thematic Analysis is a research method that has gained popularity in recent years due to the numerous advantages of collaborative research. However, there are also some drawbacks. Here are some of the main pros and cons of using CTA:
Benefits of Collaborative Thematic Analysis
Integrating diverse perspectives
Coding large datasets in less time
Mentoring new researchers
Challenges of Collaborative Thematic Analysis
Coordinating multiple interpretations
Managing individual biases
Maintaining transparency
Time-consuming in general
Inconsistent coding from co-researchers may reduce reliability
A Step-by-Step Guide to Collaborative Thematic Analysis
Hemphill outlined various steps that are carried out after collecting and transcribing qualitative data. These steps help the team find patterns and summarize the data by identifying themes and subthemes.
The steps are done progressively to arrive at a shared understanding of the data. However, like most qualitative methods, this is an iterative process. You will return to previous steps to investigate coder disagreements, modify the codebook, add rigor to your analysis, or add more supporting data as needed.
Collaborative Thematic Analysis Steps
Phase 0: Preliminary Organization and Planning
After collecting and transcribing the data, Collaborative Thematic Analysis begins with a team meeting or group discussion. The initial meeting starts by creating a plan to analyze the data, including a project summary, data sources, guiding theories, and research questions.
The team then discusses publication goals, final authorship, and a flexible meeting plan. These discussions ensure everyone understands the project's direction from the start.
Step 0.1: Create a Shared Space for Memos
A key focus of the initial discussion is also to establish a system to catalog a shared audit trail.
Delve’s cloud-based software makes it easy to add memos to codes and to add memos to snippets, which can act as a shared journal where all researchers can share their thoughts.
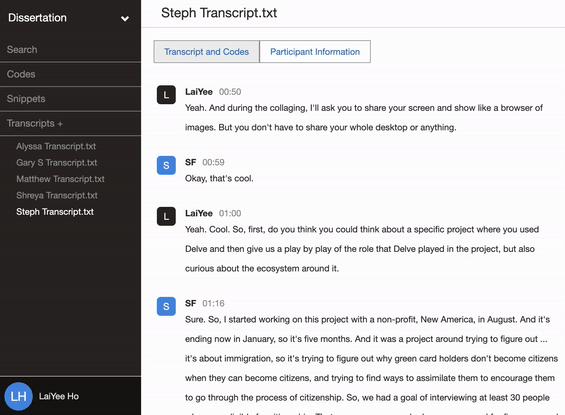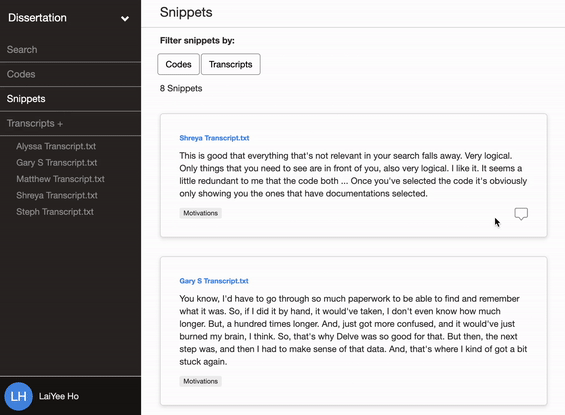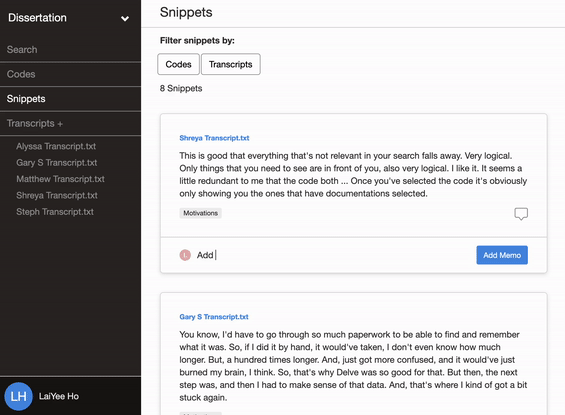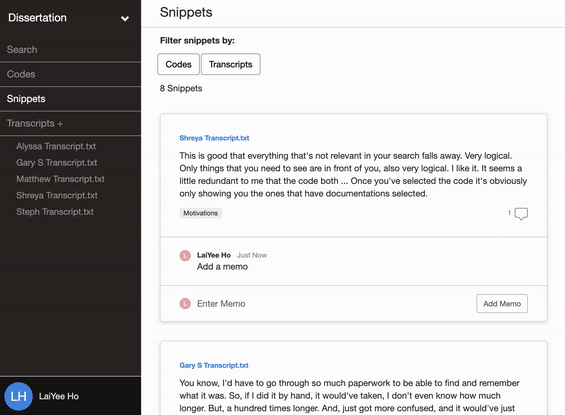
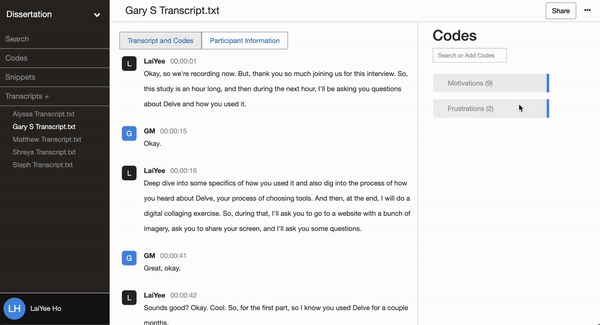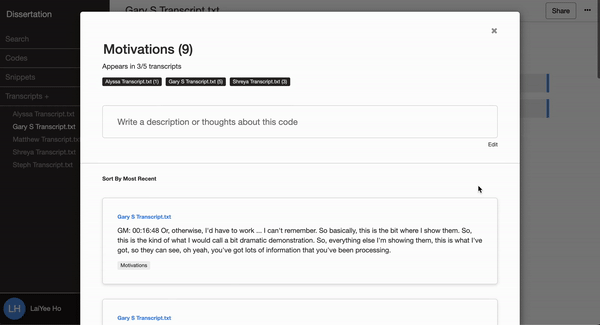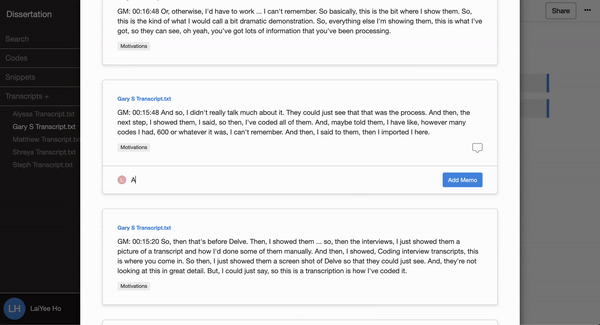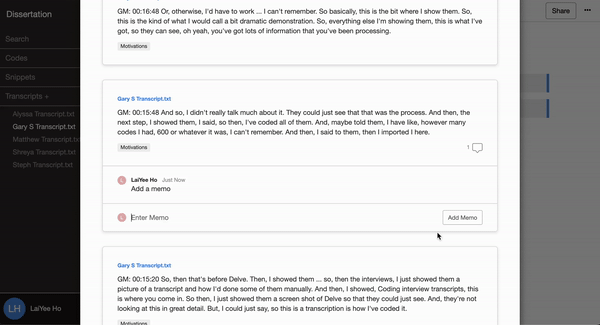
The team records these memos throughout their research and refers to the archive in the final write-up to enhance the study’s confirmability.
[Related readings: What Are Analytical Memos?]
Phase 1: Delving into the Data
One of the most difficult parts of making thematic analysis a collaborative process is that it’s an inductive approach. It’s not just a matter of applying a theoretical framework. Instead, you will be deriving themes from the data itself. Adding to the challenge, the team uncovers these themes and patterns as a group by incorporating each researcher’s perspective.
In this first phase, each researcher will be familiarizing themselves with the data. As they familiarize themselves, they can also begin to create initial codes.
Using Delve, the team can create shared codes using the tool’s cloud-based storage. This eliminates the need for manual data input and automatically saves work during each researcher’s session. Everybody on the team can then work together off the same set of codes.
Step 1.1: Every team member familiarizes themselves with the data
This first step is similar to conducting thematic analysis as an individual. Each researcher reads through the transcripts and actively observes meanings and patterns that appear across your data set. The goal is to gain a deep understanding of the data by engaging in repeated readings.
You aren’t creating formal codes yet but it helps to jot down thoughts about potential codes to create in subsequent phases. Here, Delve’s memo functionality is a particularly efficient option.
Step 1.2: Create your initial codes
After the team is familiar with the data, each member of the research team reads and codes a set of 2-3 different data transcripts (e.g. field notes, interviews, and reflection journal entries). They use coding software like Delve or manual methods to code and also start categorizing the data into generative categories.
Each researcher creates initial codes that represent the meanings and patterns they discovered. They all store their codes in their own codebooks and record memos in software like Delve. Discuss coding decisions and memos entries in each team discussion
Next, everyone independently reads through the data again. The goal is to begin identifying salient excerpts and apply the appropriate codes to them. Excerpts that represent the same meaning should have the same code applied. The process is informal but helps steer the analysis.
Step 1.3: Discuss your initial codes
With some initial codes and categories created, researchers should discuss and compare their transcripts and memos. It is also helpful for each researcher to provide a brief overview of each transcript they read. You want to uncover recurring patterns in the transcripts and identify any unique or contradicting negative cases that emerge.
As part of this process, researchers may start to notice nascent themes. While defining themes comes later, it can be helpful to start discussing what you have seen in the team’s memos and team discussions. Keep in mind that this audit trail helps structure the final write-up later on.
The team also discusses their memos, which often capture initial reactions, interpretations, and ideas about the data. These memos can offer valuable insights and potential avenues for further analysis. Try to make time to review coding decisions and memos in each team discussion.
The team can then review and adjust their research questions based on this preliminary analysis. Based on these discussions, the team plans the next steps in their analysis. This involves deciding whether to continue with more rounds of initial coding or move on to the next phase of formal theme development. They also determine which transcripts to analyze next.
Step 1.4 Iterate Through Phase 1
Researchers will continue to iterate through each portion of Phase 1. There should be at least 3-4 rounds of reading, initial coding, and group discussions as you delve deeper into your data.
ℹ️ Researchers should have access to each other's codes and memos throughout Collaborative Thematic Analysis. This approach involves developing themes together, making seeing each other's work important. One option is to review each other's work before group meetings using the memos as a starting point.
That being said, hiding other researchers’ coded data before working on transcripts can be beneficial. Delve's "hide how others coded" feature streamlines this process, allowing each researcher to form their own unbiased opinion before reviewing others' coding.
⚠️ Collaborative thematic analysis is different from intercoder reliability, where you must code separately for the intercoder reliability score to be valid. Collaborative coding is a cornerstone of CTA that only enhances the richness and rigor of the study overall.
Phase 2: Group Codes into Themes
Step 2.1 Do another round of coding individually
The group should now assign another batch of 3-4 different transcripts to code individually. Continue adding new initial codes and categories to your individual codebooks and memos.
If your team decides to use Delve’s coding software, here’s what the process looks like:
Step 2.2 Individually group initial codes into themes
After coding the new batch of transcripts, the group will see more patterns and potential themes emerge. Each researcher keeps creating their own set of initial themes from their initial coding. You want everyone to consolidate their own codes and themes (as depicted in the video) to then discuss as a team.
At this stage, researchers have had several discussions, and while their coding may still be independent, they have a better sense of how closely their coding aligns. Naturally, this can influence their coding decisions and gradually guide everyone toward a shared direction.
⚠️ These initial phases may start to feel monotonous and repetitive. However, keep in mind that the iterative nature of Collaborative Thematic Analysis is what makes it such a rigorous research method! The more thorough these iterative rounds are, the more rich the data becomes.
Step 2.3 Meet to discuss themes
With some initial themes created, the research team discusses emergent themes. Each researcher presents the themes they've identified. This allows for comparison and contrast of the different themes each person identified.
Examine how themes intersect or diverge. It is important to identify patterns that emerge across multiple researchers' themes. Recognizing these similarities is an elemental aspect of thematic analysis. Any disparities in theme identification should be openly discussed and clarified.
It is okay for themes to not align at this point. Use team discussions as an open forum to discuss or debate thematic disagreements. Themes may never perfectly align and these discussions are another reason that Collaborative Thematic Analysis is such a detail-rich approach.
ℹ️ One way to approach the discussions is to contrast each theme to the initial research questions. This can help prioritize themes that are most critical to the study. If relevant, the team can discuss how the themes may connect to pre-existing theories or research. This can provide further depth and context to the overall analysis.
If the team starts to agree on specific themes, it is now acceptable for each team member to modify their codes to closer align with one another.
Step 2.4 Iterate Through Phase 2
As with Phase 1, the iterative process continues in Phase 2. With each coding round, team members tend to create fewer new codes and start using the existing codes and themes. Fewer codes usually indicate alignment and shared understanding among the team, which is the goal.
After each coding round, the team records their thoughts in the form of memos. These offer an overview of the coding process and should highlight two or three agreed-upon generative themes. Importantly, you should include specific data excerpts or snippets that illustrate each theme and that provide thick descriptions of each. If you use Delve to record your memos, the software automatically collates the data excerpts according to your codes.
This phase usually continues until the group has analyzed around 30% of their total data set. However, the true sign of moving on to Phase 3 is that the team agrees that they are aligning on the major emergent themes.
Phase 3: Developing a shared codebook
Up to now, each researcher has been working on their own set of codes within independent codebooks. However, now they will begin creating and using a shared codebook.
The team's collaborative analysis, facilitated by iterative coding rounds and discussions, culminates in the creation of this codebook that reflects their collective efforts.
Step 3.1 Merge the individual codebooks into one codebook
By merging everyone’s codes and themes, the group will end up with one unified codebookThis step can be carried out collectively as a group, or a single team member. Hemphill suggests that the research lead can take the initial pass at the codebook.
However, we prefer to include each researcher in this process. Allowing everyone’s voice to be heard ensures that all researchers have a chance to contribute their unique perspectives.
As the team reviews each other's codes and themes, they continue to discuss similarities and patterns that emerge. This leads to merging similar codes and themes, reducing redundancy and ensuring consistency in the analysis. By consolidating codes and refining themes, the team creates a unified codebook that reflects their collective understanding.
Using research software like Delve enables you to merge codes, and end up with a unified codebook. Not only does the software preserve the initial supporting memos and notes but it streamlines the codebook creation process itself.
Step 3.2 Clean up code descriptions
After all of the codes and themes are merged into a single codebook, you may find that the code and theme descriptions can be refined or clarified.
To guide the process, you can collectively choose 1-3 snippets that best represent a specific theme or code. The team can align their understanding of the codes by referring back to their snippets and memos at the end of Phase 2 (Step 2.4).
ℹ️ If this step was done by a single team member, this draft codebook is given to the research team so each team member can review it before the team discussion. And in the discussion, changes are made based. Then, a preliminary codebook is finalized.
Step 3.3 (optional) A peer debriefer reviews the codebook
A researcher who is familiar with the project but not involved in the data analysis serves as a peer debriefer. The peer debriefer reviews and comments on the initial codebook, and appropriate adjustments are made.
Try Delve – Software for Qualitative Analysis
Delve can help streamline both how your team codes and how they communicate.
Try a 14-day free trial of Delve.
Phase 4: Pilot Test the Codebook using consensus coding
Step 4.1 Each team member applies the codebook to the same transcripts.
Through consensus coding, the team applies the single codebook to uncoded data by coding the same 2-3 transcripts. Consensus coding is when researchers compare coding results on a one-to-one basis to ensure there is consistency (consensus) in how codes are being applied.
Consensus coding is an exhaustive, time-consuming process that helps minimize variation among researchers in how codes are applied or interpreted, ensuring greater coding consistency.
As each researcher codes a copy of the same transcripts, they continue to record memos. The memos continue to have two important jobs: it keeps recording an audit trail for the write-up and provides more structure to the team discussions.
4.2 Use a blended approach of consensus and split coding (optional)
⌛ To save time, you can use consensus coding in the first iterations and switch to split coding later when the team feels ready. Split coding is when each coder analyzes 2-3 different transcripts and records notes in the form of memos. During discussions, the team cross-checks the coding scheme, reviews each coded transcript, and discusses their memos.
Note that split coding saves time by allowing researchers to code different transcripts, but it may lead to slightly less rigorous results. Hemphill adds that it is commonly used by smaller teams with limited time or resources.
Step 4.3 Meet as a team to compare coding results
The team continues to compare their consensus or split coding results in iterative rounds. They engage in discussions when disagreements arise until the team finds consensus. This collaborative effort helps establish coding conventions, which serve as rules to guide future coding decisions.
If required, the team also establishes rules for double coding excerpts, assigning them to two or three generative themes established within the first edition of the shared codebook. At this stage, each code should fit into one of these generative themes.
ℹ️ Throughout this phase, the codebook may be modified as necessary during each team meeting to ensure its ongoing refinement and effectiveness. Keep in mind that any changes must be collectively decided and no single researcher should make decisions for the entire team.
Step 4.4 Peer Debriefer reviews the evolving codebook (optional)
To add a layer of trust to the results, have a peer debriefer review the evolving codebook once again. Ask them to recommend any possible changes before the final coding phase ahead.
Step 4.5 Repeat Phase 4
Continue pilot testing for three to four rounds of coding before finalizing the codebook. This phase ends when the group feels confident that they are using the codebook in the same way.
Using tools like Delve’s coding comparison feature makes it easy to compare how each member is applying codes. And like the shared journal, using Delve’s cloud-based service allows the team to efficiently review work without collating data from several different sources or mediums.
Phase 5: Apply the finalized codebook to the complete dataset
Step 5.1 Assign transcripts to team members, as they code them with consensus and split coding
In the final phase of coding, you now apply the codebook to the entire data set. This includes re-coding all of the previously coded transcripts from earlier stages.
Transcripts are distributed 3-4 at a time in each iterative round of coding. Each transcript of each batch is then discussed until the group reaches a consensus on all coding decisions. The group also discusses how codes are distributed into the agreed-upon generative themes.
ℹ️ Hemphill suggests continuing to use consensus or split coding to ensure coding consistency, just as you did when coding to test pilot the codebook in Phase 4.
Step 5.2 Meet as a team to reflect on the coding process
You should also iteratively modify the codebook in the team meetings to reflect ongoing insights developed during the coding process. The team also reviews their memos in each round.
Even though you have “finalized” your codebook, it is common that adjustments to the codebook are still being made. However, finding entirely new themes in the last few transcripts is rare.
Phase 6: Review Codebook and Finalize Themes
At this stage, the research team has developed a thematic framework from the coded transcripts, which includes main themes and subthemes.
Consensus has been reached among all team members regarding this final structure, which forms the foundation of how the team presents its findings.
Phase 6.1 Final group discussion for a comprehensive review
During the final discussion, the team conducts a comprehensive review of the codebook to ensure its completeness and accuracy. They then transform the codebook into a thematic structure, organizing it into main themes and subthemes that effectively capture and describe the perspectives of the respondents.
Together, they carefully review and approve the thematic structure, ensuring it aligns with their collective understanding and analysis. It is helpful to compare the design with the initial research questions to ensure coherence.
Ultimately, the approved thematic structure forms the foundation for presenting the results in the research write-up, providing a cohesive and meaningful representation of the study findings.
Reflecting on the entire process, utilizing Collaborative Thematic Analysis (CTA) facilitated the identification of recurring themes and sub-themes in the data, established clear coding conventions, and used researcher triangulation to enhance the credibility of the study.
Publishing your process
With multiple voices contributing to the analysis, it is important to outline both the research results and the process itself. Clear and open communication about the research process is a good way to alleviate concerns about the reliability and trustworthiness of the research.
So, while many researchers focus mostly on the results of CTA, it is equally important to outline the process as well. Otherwise, fellow researchers may question the validity of those results.
More ways to improve trustworthiness in collaborative thematic analysis
We have already touched upon a few ways to improve trust during CTA, such as peer debriefing. Hemphill notes that other researchers suggest the following techniques:
Negative case analysis: As mentioned within the steps, researchers seek out data that contradicts the main findings. If they are not able to find many negative cases, this enhances credibility (Lincoln & Guba, 1985).
Data triangulation: Sample data from multiple sources to ensure that findings are comprehensive, rigorous, and dependable (Brewer & Hunter, 1989).
Wrapping Up
Collaborative thematic analysis is an effective method for researchers to work together and communicate ideas. However, it can be challenging and time-consuming to work with a group. To improve the transparency of this process, it is important to be transparent about the entire process and how it unfolds.
As outlined above, Hemphill and others have developed best practices to streamline the CTA process. These guidelines provide an efficient approach, and the steps can be used to guide the work. This approach is particularly helpful for those who are new to qualitative research.
Delve: Smart Collaboration for Remote Researchers
Tools like Delve facilitate collaborative research in the era of remote work, eliminating research bottlenecks. With video chat software for group discussions and Delve as a unified, cloud-based platform, work remains intact and everyone stays on the same page throughout the process.
Whether for collaborative coding or individual projects, here’s how Delve can help:
References
Hemphill, M. A. & Richards, K. A. R. (2018). A practical guide to collaborative qualitative data analysis. Journal of Teaching in Physical Education, 37(2), 225–231. https://doi.org/10.1123/jtpe.2017-0084
Brewer, J., & Hunter, A. (1989). Multimethod research: A synthesis of styles.
Lincoln, Y. S., & Guba, E. G. (1985). Naturalistic Inquiry. Beverly Hills, CA: Sage Publications, Inc.
Cite This Article
Delve, Ho, L., & Limpaecher, A. (2023c, June 14). Collaborative Thematic Analysis in Qualitative Research https://delvetool.com/blog/collaborative-thematic-analysis